If your Data as a Service (DaaS) is based on a Gather/Process/Publish cycle, Pervasive Data Integrator can provide a great off-the-shelf implementation. For over 20 years, Pervasive has integrated, transformed, loaded, and extracted data for tens of thousands of customers. The architecture presented in this article is based on Data Integrator and is highly scalable, performant, and secure.
This article refers to an architecture diagram at http://www.bekwam.net/images/bekwam_daas_arch.gif.
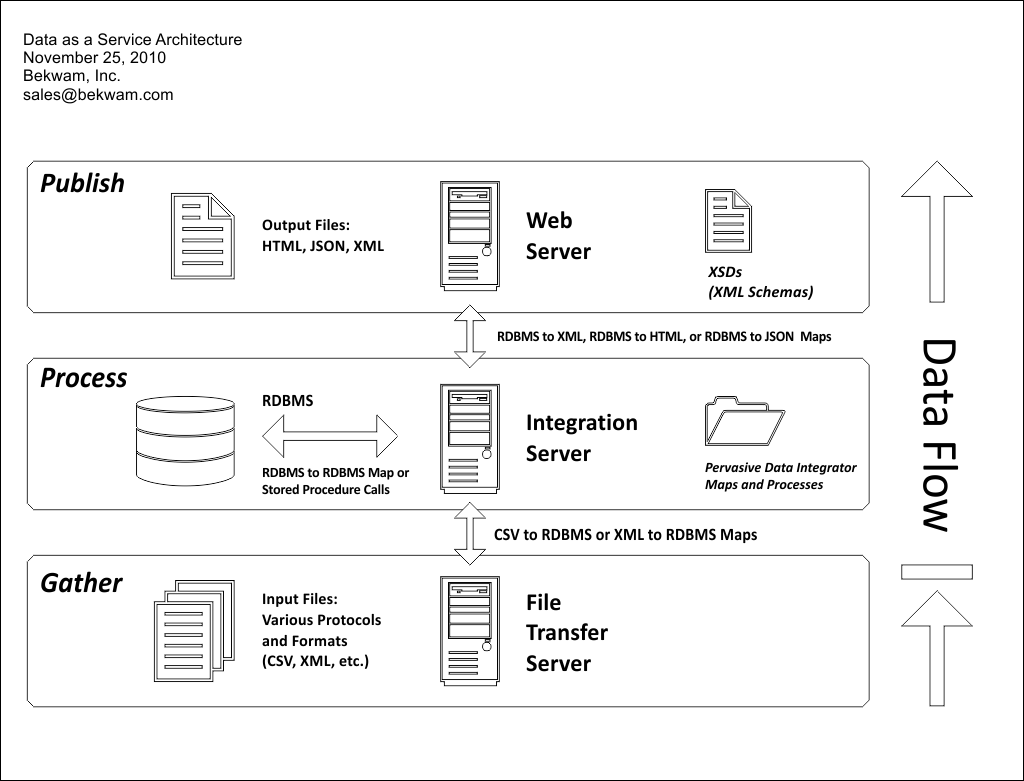
GATHER
The Gather/Process/Publish cycle is a sequence of processes scheduled throughout the day in accordance with latency requirements. The Gather stage includes retrieving and organizing data input files. These files can be of many different formats including comma-separated values (CSV) or XML. The files can be transmitted using a variety of protocols including HTTP and FTP plus their secure variants.
PROCESS
The Process stage shapes the data through normalizing and prepares specialized views of the data. This is a typical loading and transforming process that is the major strength of Pervasive Data Integrator. Maps, code created in Pervasive's Map Designer, load the data files from the Gather stage into the database. Additional Maps or RDBMS stored procedures perform inter-database transformations (sources can be individual tables or complex SQL queries). Stored procedures are invoked by Pervasive Process Designer.
PUBLISH
The Publish stage uses maps to extract data from the RDBMS into a variety of formats that are consumed by the end users. These formats can include CSV, XML, HTML, or even JSON. For complex data structures, XML schemas (XSD) can be stored to provide descriptions of the data to the user. The Publish stage delivers data to the user using a standard web server. Off-the-shelf, a standard web server provides security and caching (manipulating timestamps).
User security is handled in both the Gather and Publish stages using partitions that are meaningful to the business. For example, data can be gathered in folders owned by a particular data producer. A folder structure for end users is used in the Publish stage. The web servers handle the user authorization and authentication.
The separation of the file transfer (inbound and outbound) from the integration server can be reinforced with firewalls.
In this architecture, Pervasive Data Integrator is a compelling alternative to custom coding. As new users are added to the DaaS, a consistent way of handling slight variations in data presentation is needed. The graphical tool is highly productive and less error prone. Pervasive Process Designer is a graphical alternative to shell or Python scripting that provides logging and configuration services to Map Designer. Jobs are scheduled using a simple technology like the Windows Scheduler or cron or a more robust job scheduler like Control-M (PDF).
This post is replicated from http://my.opera.com/walkerca/blog/daas.
{kind=link}
For a good way to organize the Gather process, look at Josef Richberg's Drop Box technique. http://josef-richberg.squarespace.com/journal/2010/2/24/managing-user-data-and-response-through-drop-boxes.html
ReplyDeleteI've done this with an Apache HTTP Server controlling the intake folders.