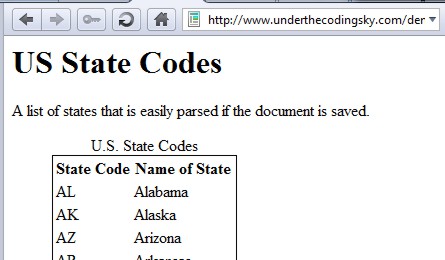
Take, for example, a web page displaying a table of 50 U.S. states and state codes. The underlying HTML contains a table with elements for the state code and the state name: States HTML.
If you save this file, you can build a schema for the file using Extract Schema Designer. Load the saved HTML file into Extract Schema Designer and mark off the lines and fields of interest. Extract Extract Schema Designer will produce a .cxl file that will be the source connector for a map. After setting up the source in Map Designer, set up the target (to an RDBMS table), then map the fields. In Part 2 of the tutorial, I use the Map by Position feature to quickly map the source fields to target fields since the names ('state_code' versus 'state_cd') don't completely match.
It's more robust to use a well-defined SOA or RESTful service and if the lines of HTML are compressed, it may not be worth the effort to screen scrape. However, with many sites using well-formed XHTML, you may get the data you need quickly. Make sure that you are legally allowed to load the data in your database first.
This post was replicated from http://my.opera.com/walkerca/blog/screen-scraping-a-web-service.
Hi,
ReplyDeleteScreen scraping is normally associated with collecting visual data from a source, instead of parsing data as in web scraping. Thanks for your more information.
Extract Data From Website